- ¿Cómo agrego un rechazo en robots txt??
- ¿Qué está prohibido en robots txt??
- ¿Cómo ignoro robots txt??
- ¿Robots txt es legalmente vinculante??
- ¿El mapa del sitio debe estar en formato robots txt??
- ¿Qué tipo de páginas se deben excluir a través de robots txt??
- ¿Cómo se comprueba si robots txt está funcionando??
- ¿Dónde se encuentra el archivo txt del robot??
- ¿Qué debe contener el robot TXT??
- ¿Qué pasa si desobedeces a robots txt??
- ¿Los motores de búsqueda ignoran los robots txt??
- ¿Google respeta los robots txt??
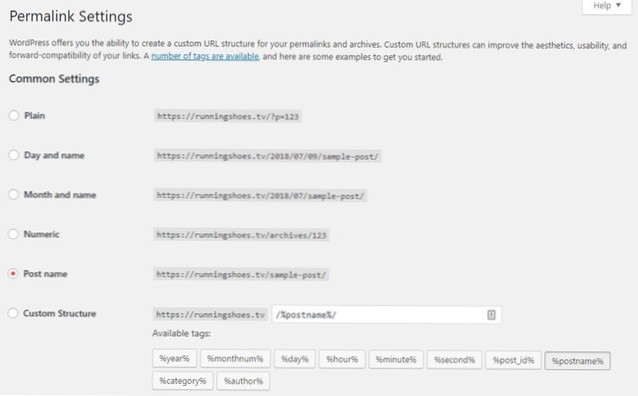
¿Cómo agrego un rechazo en robots txt??
Comience estableciendo el término de agente de usuario. Lo configuraremos para que se aplique a todos los robots web. Haga esto usando un asterisco después del término de agente de usuario, como este: Luego, escriba "Disallow:" pero no escriba nada después de eso.
¿Qué está prohibido en robots txt??
No permitir directiva en robots. TXT. Puede decirle a los motores de búsqueda que no accedan a ciertos archivos, páginas o secciones de su sitio web. Esto se hace usando la directiva Disallow.
¿Cómo ignoro robots txt??
Puedes ignorar a los robots. txt para su araña Scrapy usando la opción ROBOTSTXT_OBEY y establezca el valor en False.
¿Robots txt es legalmente vinculante??
No hay ninguna ley que establezca que / robots. txt debe ser obedecido, ni constituye un contrato vinculante entre el propietario del sitio y el usuario, pero tener un / robots. txt puede ser relevante en casos legales. Obviamente, IANAL, y si necesita asesoramiento legal, obtenga los servicios profesionales de un abogado calificado.
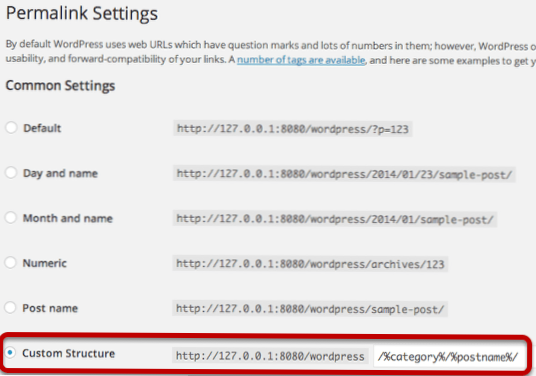
¿El mapa del sitio debería estar en formato robots txt??
Los mapas de sitio XML también pueden contener información adicional sobre cada URL, en forma de metadatos. Y al igual que los robots. txt, un mapa del sitio XML es imprescindible. No solo es importante asegurarse de que los robots de los motores de búsqueda puedan descubrir todas sus páginas, sino también ayudarlos a comprender la importancia de sus páginas.
¿Qué tipo de páginas se deben excluir a través de robots txt??
Si su página web está bloqueada con un archivo robots. txt, aún puede aparecer en los resultados de búsqueda, pero el resultado de la búsqueda no tendrá una descripción y se verá así. Se excluirán los archivos de imagen, de video, PDF y otros archivos que no sean HTML.
¿Cómo se comprueba si robots txt está funcionando??
Pon a prueba tus robots. archivo txt
- Abra la herramienta de prueba para su sitio y desplácese por los robots. ...
- Escriba la URL de una página de su sitio en el cuadro de texto en la parte inferior de la página.
- Seleccione el agente de usuario que desea simular en la lista desplegable a la derecha del cuadro de texto.
- Haga clic en el botón TEST para probar el acceso.
¿Dónde se encuentra el archivo txt del robot??
Los robots. El archivo txt debe estar ubicado en la raíz del host del sitio web al que se aplica. Por ejemplo, para controlar el rastreo en todas las URL debajo de http: // www.ejemplo.com /, los robots. El archivo txt debe estar ubicado en http: // www.ejemplo.com / robots.TXT .
¿Qué debe contener el robot TXT??
txt contiene información sobre cómo debe rastrear el motor de búsqueda, la información que se encuentre allí indicará más acciones del rastreador en este sitio en particular. Si los robots. txt no contiene ninguna directiva que no permita la actividad de un agente de usuario (o si el sitio no tiene un archivo robots.
¿Qué pasa si desobedeces a robots txt??
3 respuestas. El estándar de exclusión de robots es puramente informativo, depende completamente de usted si lo sigue o no, y si no está haciendo algo desagradable, es probable que no suceda nada si elige ignorarlo.
¿Los motores de búsqueda ignoran los robots txt??
Acceso total para todos los bots
En otras palabras, los motores de búsqueda lo ignoran. Es por eso que esta directiva de rechazo no tiene ningún efecto en el sitio. Los motores de búsqueda aún pueden rastrear todas las páginas y archivos.
¿Google respeta los robots txt??
Google anunció oficialmente que GoogleBot ya no obedecerá a Robots. txt directiva relacionada con la indexación. Editores que confían en los robots. txt La directiva noindex tiene hasta el 1 de septiembre de 2019 para eliminarla y comenzar a usar una alternativa.